这里将要介绍使用本地部署的LLM,如何使用LlamaIndex构建RAG系统。
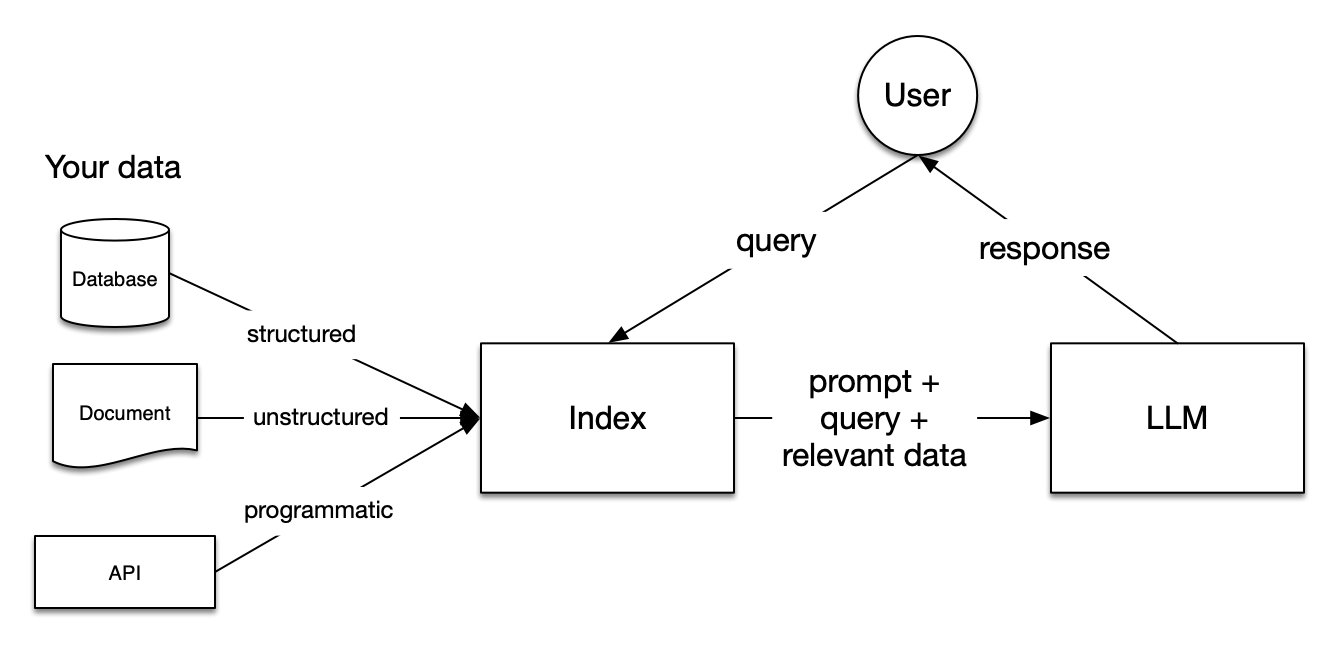
主要流程:

-
RAG 是一种基于检索增强生成(Retrieval-Augmented Generation)的技术,它通过检索相关文档来增强生成模型的输出。RAG可以用于各种任务,包括问答、摘要、翻译等。
-
LlamaIndex 是一个简单、灵活的数据框架,用于将自定义数据源连接到大型语言模型(LLMs)。它支持多种数据源,包括文本文件、数据库、API等,并且可以轻松地扩展到新的数据源。它还提供了丰富的API,使得构建RAG系统变得非常简单。
-
Ollama 是一个开源的LLM部署工具,允许用户在本地电脑上运行各种大型语言模型(LLMs)。它的主要特点包括:
- 本地化运行 - 让用户可以在自己的电脑上离线运行AI模型,而不需要连接到云服务
- 支持多种模型 - 包括Llama 2、Mistral、Vicuna等多种开源语言模型
- 简单易用 - 提供了简单的命令行界面和API接口
- 资源效率 - 针对桌面环境进行了优化,减少了资源消耗
- 隐私保护 - 因为模型在本地运行,所以数据不会发送到外部服务器
-
Milvus 是一个开源的向量数据库,可以用于存储和检索高维向量数据。它支持多种向量存储引擎,包括FAISS、Pinecone、Qdrant等,并且可以轻松地扩展到新的存储引擎。它还提供了丰富的API,使得构建RAG系统变得非常简单。
环境准备
这里使用Ollama本地部署模型,生产环境可以考虑使用云服务,或者[vLLM](https://github.com/vllm-project/vllm)进行部署。
安装Ollama
linux 环境下:
curl -fsSL https://ollama.com/install.sh | sh
Mac 和 Windows 环境下, 可以在官网下载。
Dcoker Compose 安装Milvus
Milvus 在 Milvus 资源库中提供了 Docker Compose 配置文件。要使用 Docker Compose 安装 Milvus,只需运行
Download the configuration file
wget https://github.com/milvus-io/milvus/releases/download/v2.5.9/milvus-standalone-docker-compose.yml -O docker-compose.yml
Start Milvus
sudo docker compose up -d
Creating milvus-etcd ... done
Creating milvus-minio ... done
Creating milvus-standalone ... done
使用以下命令检查容器是否启动并运行:
❯ docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
milvus-etcd quay.io/coreos/etcd:v3.5.18 "etcd -advertise-cli…" etcd 20 minutes ago Up 20 minutes (healthy) 2379-2380/tcp
milvus-minio minio/minio:RELEASE.2023-03-20T20-16-18Z "/usr/bin/docker-ent…" minio 20 minutes ago Up 20 minutes (healthy) 0.0.0.0:9000-9001->9000-9001/tcp, :::9000-9001->9000-9001/tcp
milvus-standalone milvusdb/milvus:v2.5.6 "/tini -- milvus run…" standalone 20 minutes ago Up 20 minutes (healthy) 0.0.0.0:9091->9091/tcp, :::9091->9091/tcp, 0.0.0.0:19530->19530/tcp, :::19530->19530/tcp
安装uv
uv 使用 Rust 开发的 Python 包和项目管理器。
mac OS 和 linux :
curl -LsSf https://astral.sh/uv/install.sh | sh
uv 管理项目依赖和环境,支持lockfiles, workspaces 等, 类似于 rye 和 poetry。
uv init
uv venv --python=3.10 # 创建项目虚拟环境
source .venv/bin/activate # 激活项目虚拟环境
安装依赖
代码中需要依赖 pymiluvs , llamaindex 和 ollma,使用下面的命令安装依赖:
uv add pymilvus
uv add llama-index-vector-stores-milvus
uv add llama-index
uv add llama-index-llms-ollama
uv add llama-index-embeddings-ollama
开始
获取数据
这里使用的数据是,保存在Github上Paul Graham的一篇文章。
>mkdir -p 'data/paul_graham/'
>wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt'
from llama_index.core import SimpleDirectoryReader
# load documents
documents = SimpleDirectoryReader(
input_files=["./data/paul_graham_essay.txt"]
).load_data()
print("Document ID:", documents[0].doc_id)
out:
Document ID: 41314907-75fa-4bba-b6d9-6eb36e6add24
创建索引
这里使用的是的嵌入模型是:modelscope.cn/Embedding-GGUF/gte-Qwen2-1.5B-instruct-Q4_K_M-GGUF:latest , 数据保存到 Milvus 中:
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.embeddings.ollama import OllamaEmbedding
settings.embed_model = OllamaEmbedding(
model_name="modelscope.cn/Embedding-GGUF/gte-Qwen2-1.5B-instruct-Q4_K_M-GGUF:latest",
base_url="http://127.0.0.1:11434",
)
连接上本地部署的 Milvus 服务:
from llama_index.vector_stores.milvus import MilvusVectorStore
vector_stores = MilvusVectorStore(
collection_name="t_doc",
dim=1536,
uri="http://127.0.0.1:19530",
overwrite=False,
similarity_metric="COSINE",
)
storage_context = StorageContext.from_defaults(vector_store=vector_stores)
index = VectorStoreIndex.from_documents(
docs,
storage_context=storage_context,
show_progress=True,
)
现在我们有了文档,可以创建索引并插入文档。
其中:
collection_name: Milvus 集合名称dim: 嵌入向量维度uri: Milvus 服务地址overwrite: 是否覆盖已存在的集合similarity_metric: 相似度度量方法
查询数据
现在我们已经将文档存储到了索引中,可以针对索引提出问题。
使用的同样的嵌入模型, 从 Milvus 中加载向量,然后创建索引,最后查询数据。
embed_model = OllamaEmbedding(
base_url="http://127.0.0.1:11434",
model_name="modelscope.cn/Embedding-GGUF/gte-Qwen2-1.5B-instruct-Q4_K_M-GGUF:latest",
)
Settings.llm = Ollama(
base_url="http://127.0.0.1:11434",
model="qwen2.5:7b-instruct-q4_K_M",
request_timeout=30,
)
vector_stores = MilvusVectorStore(
collection_name="t_doc",
dim=1536,
uri="http://127.0.0.1:19530",
overwrite=False,
similarity_metric="COSINE",
)
index = VectorStoreIndex.from_vector_store(
vector_store=vector_stores,
embed_model=embed_model,
)
query_engine = index.as_query_engine()
response = query_engine.query("What is AI?")
print(response)
❯ uv run main.py
2025-04-19 15:00:40,435 [DEBUG][_create_connection]: Created new connection using: 3d9484d069f84709bd3befbc643cc588 (async_milvus_client.py:600)
INFO:httpx:HTTP Request: POST http://127.0.0.1:11434/api/embeddings "HTTP/1.1 200 OK"
INFO:httpx:HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
AI, or Artificial Intelligence, in the early 1980s as described, involved creating programs that could understand natural language to a certain extent. The speaker believed at first that AI was about teaching programs like SHRDLU more words and expanding their formal representations of concepts. However, he later realized that this approach had significant limitations because there was an unbridgeable gap between the subset of natural language these early programs could handle and true human-like understanding. He came to see AI as a field with potential but one that was fundamentally flawed in its initial approaches, particularly those relying on explicit data structures to represent concepts without achieving actual intelligence.
在博客原文中的相关SHRDLU:
❯ rg SHRDLU
data/paul_graham/paul_graham_essay.txt
25:AI was in the air in the mid 1980s, but there were two things especially that made me want to work on it: a novel by Heinlein called The Moon is a Harsh Mistress, which featured an intelligent computer called Mike, and a PBS documentary that showed Terry Winograd using SHRDLU. I haven't tried rereading The Moon is a Harsh Mistress, so I don't know how well it has aged, but when I read it I was drawn entirely into its world. It seemed only a matter of time before we'd have Mike, and when I saw Winograd using SHRDLU, it seemed like that time would be a few years at most. All you had to do was teach SHRDLU more words.
29:For my undergraduate thesis, I reverse-engineered SHRDLU. My God did I love working on that program. It was a pleasing bit of code, but what made it even more exciting was my belief — hard to imagine now, but not unique in 1985 — that it was already climbing the lower slopes of intelligence.
33:I applied to 3 grad schools: MIT and Yale, which were renowned for AI at the time, and Harvard, which I'd visited because Rich Draves went there, and was also home to Bill Woods, who'd invented the type of parser I used in my SHRDLU clone. Only Harvard accepted me, so that was where I went.
37:What these programs really showed was that there's a subset of natural language that's a formal language. But a very proper subset. It was clear that there was an unbridgeable gap between what they could do and actually understanding natural language. It was not, in fact, simply a matter of teaching SHRDLU more words. That whole way of doing AI, with explicit data structures representing concepts, was not going to work. Its brokenness did, as so often happens, generate a lot of opportunities to write papers about various band-aids that could be applied to it, but it was never going to get us Mike.
自定义查询流程
当使用 QueryEngine 时,LlamaIndex 内部会使用 Prompt 来指导 LLM 如何利用检索到的信息来回答用户的查询。
自定义流程中: 可以获取检索结果,然后自己构建 Prompt 调用 LLM 进行进一步处理。
使用 Retriever 获取 Top-K,然后自定义 Prompt 进行 LLM 验证
这种方法更灵活,控制力更强,专注于“识别关联”而非“生成答案”。
- 使用 Retriever 获取节点:
retriever = index.as_retriever(similarity_top_k=5) # 获取最相似的 5 个
question_text = "What is AI"
retrieved_nodes = retriever.retrieve(question_text)
- 构建自定义 Prompt 调用 LLM:
目标: 让 LLM 从检索到的 retrieved_nodes 中选出答案。 Prompt 示例:
from llama_index.llms.ollama import Ollama
llm = Ollama(
base_url="http://127.0.0.1:11434",
model="qwen2.5:7b-instruct-q4_K_M",
request_timeout=30,
)
retriever = index.as_retriever(similarity_top_k=5) # 获取最相似的 5 个
question_text = "What is AI"
retrieved_nodes = retriever.retrieve(question_text)
context_str = "\n\n".join([f"{node.text}" for node in retrieved_nodes])
prompt_template = f"""
"{question_text}"
Context:
---
{context_str}
---
"""
response = Settings.llm.complete(prompt_template)
print(response.text)
Last modified on 2025-04-19