MCP(Model Context Protocol) 里两种流式传输机制的差异是什么?以及为什么社区从 SSE(Server-Sent Events) 慢慢转向 Streamable HTTP?
1. SSE 和 Streamable HTTP 在 MCP 里的区别
SSE (Server-Sent Events)
- 协议:基于 HTTP/1.x 的单向推送,服务器持续通过
Content-Type: text/event-stream推送事件。 - 特性:
- 只能 服务器 → 客户端 单向流。
- 事件是基于文本的、UTF-8 编码。
- 连接保持长时间打开,数据通过
\n\n分隔。 - 浏览器原生支持
EventSource,实现简单。
- 在 MCP 中的使用:主要用于模型响应的流式传输(像 ChatGPT 一样逐字输出)。
Streamable HTTP
-
协议:利用 HTTP 响应体本身作为流通道,客户端读取分块(chunked transfer)或 HTTP/2 帧。
-
特性:
- 不依赖额外事件封装,直接在响应体中发送 JSON/二进制片段。
- 支持 双向交互(尤其在 HTTP/2/HTTP/3 中可以用 request/response stream 组合实现)。
- 传输效率更高,数据结构更灵活(不限制必须是 UTF-8 文本)。
-
在 MCP 中的使用:作为替代 SSE 的新流式响应标准,既能流式传输模型输出,也能嵌入更多元数据。
在构建知识库时,分段(Chunking)是一个至关重要的步骤,尤其是在与大型语言模型(LLM)结合使用,例如在检索增强生成(RAG)系统中。分段的目的是将长文本分割成较小的、可管理的块,以便:
- 适应LLM的上下文窗口限制: LLM有输入Token数量的限制,过长的文本需要被切分。
- 提高检索相关性: 较小的、语义连贯的块更容易在向量搜索中被精确匹配到。
- 减少计算成本: 处理更小的块可以降低嵌入(embedding)和检索的计算量。
- 降低“幻觉”风险: 提供更精确、上下文相关的知识块有助于LLM生成更准确的回答。
以下是常见的知识库分段方式,以及它们各自的优缺点和适用场景:
1. 基于固定大小的分段 (Fixed-Size Chunking)
这是最简单、最直接的分段方式。
- 方式: 将文档按照固定的字符数或Token数进行切分,通常会设置一个重叠量(overlap)。
- 示例: 每500个字符切成一个块,重叠100个字符。
- 优点:
- 实现简单,处理速度快。
- 适用于任何文本类型。
- 缺点:
- 破坏语义完整性: 可能会在一个句子的中间或段落的中间进行切分,导致上下文缺失或语义中断。
- 检索到的块可能不包含完整的概念,降低RAG的效果。
- 适用场景:
- 对语义完整性要求不高的简单文本。
- 初步处理或需要快速处理大量文档时。
2. 基于标点符号或结构的分段 (Delimiter-Based / Structural Chunking)
这种方式尝试在文本的自然断点处进行切分,以保留更多的语义完整性。
- 方式:
- 句子级分段: 将文档按句子切分(例如,遇到句号、问号、叹号等)。
- 段落级分段: 将文档按段落切分(例如,遇到连续的换行符)。
- 标题/章节级分段: 根据文档的标题、副标题、章节等结构信息进行切分。这通常需要解析文档的格式(如Markdown、HTML、PDF结构等)。
- 优点:
- 语义完整性较好: 尽量保持句子或段落的完整性,减少语义中断。
- 实现相对简单,处理效率较高。
- 缺点:
- 无法处理长句子/长段落: 如果一个句子或段落太长,仍然可能超出LLM的上下文限制。
- 依赖文档结构: 对于结构不明确或混杂的文档,效果可能不佳。
- 适用场景:
- 大多数散文体文档(文章、报告、博客)。
- 有清晰标题和章节结构的文档。
3. 递归字符文本拆分器 (Recursive Character Text Splitter)
这是 LangChain 等框架中推荐的通用文本分段策略,结合了固定大小和结构化切分的思想。
- 方式: 尝试按一系列分隔符(如
"\n\n"、"\n"、" "、"")递归地切分文本。它会优先使用更高级别(通常表示更大语义单元)的分隔符进行切分,如果切分后的块仍然过大,则继续使用下一个分隔符进行切分,直到所有块都小于指定大小,并通常带有重叠。 - 优点:
- 兼顾语义和长度: 尽可能保持语义完整性的同时,确保块大小符合要求。
- 通用性强,适用于多种文本类型。
- 提供重叠机制,有助于保留上下文信息。
- 缺点:
- 对于高度非结构化或语义关联性复杂的文本,可能仍有局限。
- 适用场景:
- 目前最常用且推荐的通用分段策略,适用于绝大多数知识库场景。
4. 父子分段 (Parent-Child Chunking / Small-to-Large Chunking)
这是一种更高级的策略,旨在平衡检索精度和上下文完整性。
Annotated
typing.Annotated 在 Python3.9 版中引入,用于为类型注解添加元数据。作为 PEP 593 -- Flexible function and variable annotations 的一部分被添加到 typing 模块中。使用 Annotated,Python 环境必须是 3.9 或更高版本。
typing.Annotated 的核心作用是为现有的 Python 类型添加元数据(metadata)。它本身并不执行任何运行时的类型检查或验证。可以将
Annotated 看作是一个类型装饰器,它允许你将额外的信息(可以是任何 Python 对象) 与一个类型关联起来。
这个设计的主要目的是为了让第三方工具能够更好地理解类型注解,从而提供更丰富的功能,例如类型检查、文档生成等,且无需修改 Python 的核心类型系统。通过使用 Annotated,开发者可以更灵活地表达类型信息,使代码更加清晰和可维护,
Pydantic
Pydantic 是一个 Python 库,主要用于数据验证和解析。它通过 Python 的类型提示 (type hints) 来定义数据的结构,并在运行时验证数据的有效性。
以下是 Pydantic 的主要用途和优点:
数据验证 (Data Validation): 这是 Pydantic 最核心的功能。你可以使用 Pydantic 模型清晰地定义预期的数据结构和类型。当接收到外部数据(例如,来自 API 请求、配置文件、用户输入等)时,Pydantic 会自动根据你定义的模型进行验证。如果数据不符合预期类型或约束,Pydantic 会抛出详细的错误信息,告诉你哪些字段出了问题以及具体原因。数据解析 (Data Parsing): 除了验证,Pydantic 还能将输入数据解析成 Python 对象。即使输入数据是字符串、数字或其他格式,Pydantic 也会尝试将其转换为模型中定义的 Python 类型。例如,一个字符串 “123” 可以被解析成 int 类型。- 数据序列化 (Data Serialization): Pydantic 模型可以将 Python 对象序列化为其他格式,如 JSON。这对于构建 API 接口非常有用,因为你需要将 Python 对象转换为 JSON 格式发送给客户端。
- 类型提示的强大利用: Pydantic 充分利用了 Python 3.6+ 引入的类型提示。通过类型提示,你可以清晰地表达数据的预期结构,这不仅方便了 Pydantic 的验证和解析,也提高了代码的可读性和可维护性,并能与 MyPy 等静态类型检查工具良好集成。
- JSON Schema 生成: Pydantic 可以根据你的模型自动生成 JSON Schema。JSON Schema 是一种描述 JSON 数据结构的标准化方式,这对于 API 文档生成和与其他系统进行数据交互非常有用。
- 与 Web 框架集成: Pydantic 与许多流行的 Python Web 框架(如 FastAPI、Starlette)无缝集成。FastAPI 甚至在底层 heavily rely on Pydantic 来处理请求和响应的数据验证和序列化。
- 自定义验证器 (Custom Validators): 除了基本的类型验证,Pydantic 还允许你定义自定义的验证逻辑,以满足更复杂的业务规则。你可以编写函数来检查字段的值是否符合特定的要求。
- 数据清洗和转换 (Data Cleaning and Transformation): 在验证过程中,Pydantic 还可以对数据进行清洗和转换。例如,你可以定义将字符串自动去除首尾空格,或者将日期字符串转换为 datetime 对象。
总而言之,Pydantic 主要用于确保你的 Python 应用程序接收和处理的数据是有效和符合预期的。它可以帮助你减少因数据格式错误而引发的 bug,提高代码的健壮性和可靠性,并简化数据处理相关的开发工作。
前提条件:
- 安装
huggingface-cli:pip install huggingface_hub - 了解模型在 Hugging Face Hub 上的位置: 你需要知道模型仓库名称和 GGUF 文件名。GGUF 文件通常以
.gguf结尾。
步骤:
-
登录 Hugging Face (可选但推荐):
huggingface-cli login按照提示输入你的 token (在 Hugging Face 网站的 “Settings” -> “Access Tokens” 中创建或找到)。
-
使用
huggingface-cli download命令下载 GGUF 文件:huggingface-cli download <repository_id> <filename> --local-dir <destination_directory> --local-dir-use-symlinks False参数解释:
<repository_id>: Hugging Face Hub 上模型的仓库 ID (例如TheBloke/Llama-3-8B-Instruct-GGUF).<filename>: 你想要下载的 GGUF 文件的确切文件名 (例如llama-3-8b-instruct.Q4_K_M.gguf).--local-dir <destination_directory>: 你希望将 GGUF 文件保存到的本地目录 (例如~/models/llama3).--local-dir-use-symlinks False: 设置为False以完整复制文件。
示例:
这里将要介绍使用本地部署的LLM,如何使用LlamaIndex构建RAG系统。
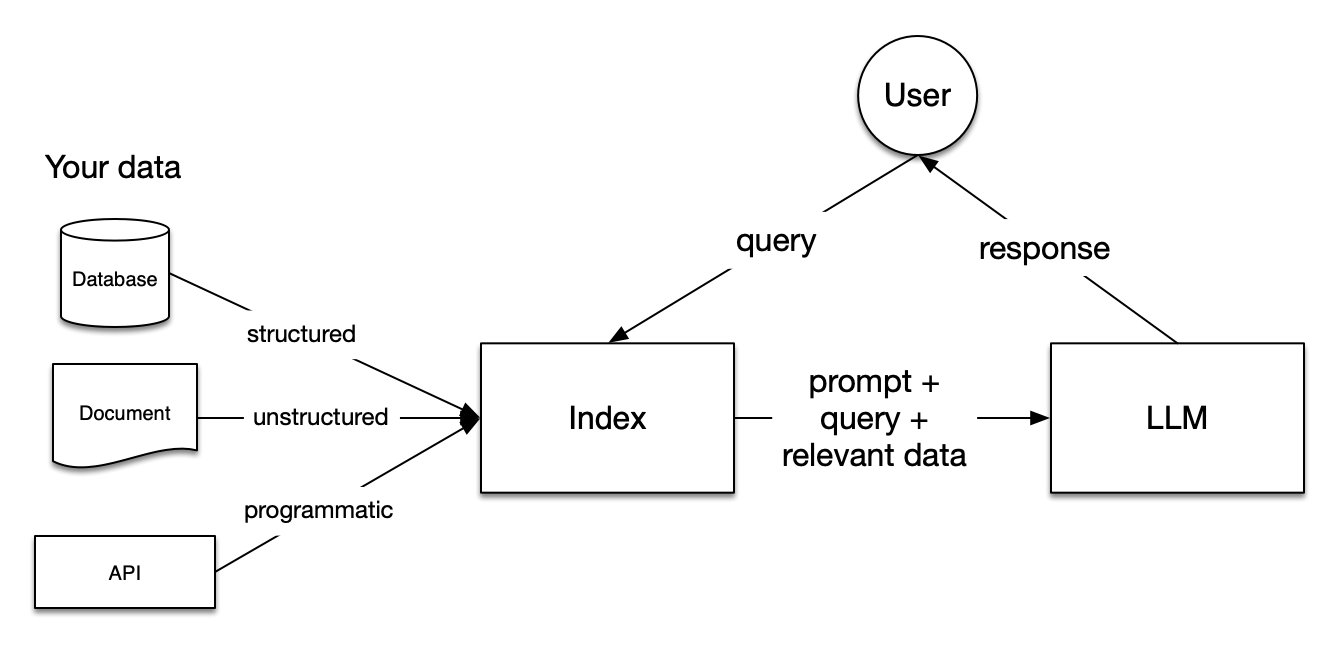
主要流程:

-
RAG 是一种基于检索增强生成(Retrieval-Augmented Generation)的技术,它通过检索相关文档来增强生成模型的输出。RAG可以用于各种任务,包括问答、摘要、翻译等。
-
LlamaIndex 是一个简单、灵活的数据框架,用于将自定义数据源连接到大型语言模型(LLMs)。它支持多种数据源,包括文本文件、数据库、API等,并且可以轻松地扩展到新的数据源。它还提供了丰富的API,使得构建RAG系统变得非常简单。
-
Ollama 是一个开源的LLM部署工具,允许用户在本地电脑上运行各种大型语言模型(LLMs)。它的主要特点包括:
- 本地化运行 - 让用户可以在自己的电脑上离线运行AI模型,而不需要连接到云服务
- 支持多种模型 - 包括Llama 2、Mistral、Vicuna等多种开源语言模型
- 简单易用 - 提供了简单的命令行界面和API接口
- 资源效率 - 针对桌面环境进行了优化,减少了资源消耗
- 隐私保护 - 因为模型在本地运行,所以数据不会发送到外部服务器
-
Milvus 是一个开源的向量数据库,可以用于存储和检索高维向量数据。它支持多种向量存储引擎,包括FAISS、Pinecone、Qdrant等,并且可以轻松地扩展到新的存储引擎。它还提供了丰富的API,使得构建RAG系统变得非常简单。
环境准备
这里使用Ollama本地部署模型,生产环境可以考虑使用云服务,或者[vLLM](https://github.com/vllm-project/vllm)进行部署。
安装Ollama
linux 环境下:
curl -fsSL https://ollama.com/install.sh | sh
Mac 和 Windows 环境下, 可以在官网下载。
Dcoker Compose 安装Milvus
Milvus 在 Milvus 资源库中提供了 Docker Compose 配置文件。要使用 Docker Compose 安装 Milvus,只需运行
Download the configuration file
wget https://github.com/milvus-io/milvus/releases/download/v2.5.9/milvus-standalone-docker-compose.yml -O docker-compose.yml
Start Milvus
sudo docker compose up -d
Creating milvus-etcd ... done
Creating milvus-minio ... done
Creating milvus-standalone ... done
使用以下命令检查容器是否启动并运行:
1、向量归一化
在机器学习和深度学习中,对嵌入向量进行归一化(Normalization)至关重要,它能带来多方面的益处,尤其是在涉及到相似度计算、模型训练和数据表示时。归一化通常指的是将向量的长度(或范数)缩放为单位长度(通常为 L2 范数等于 1)。以下是归一化的主要必要性:
统一尺度,公平比较:
- 避免特征尺度差异的影响: 不同的特征或模型生成的原始嵌入向量可能具有不同的尺度和范围。例如,一个模型的嵌入向量的数值可能在 -1 到 1 之间,而另一个模型的可能在 -100 到 100 之间。如果不进行归一化,在计算向量之间的距离或相似度时(如欧氏距离、点积),尺度较大的向量会占据主导地位,导致模型更关注这些尺度较大的特征,而忽略了尺度较小的特征中可能包含的重要信息。
- 确保每个特征的贡献相等: 归一化可以将所有嵌入向量的元素缩放到相似的尺度,使得每个维度在距离和相似度计算中具有更公平的权重,从而提高模型的鲁棒性和泛化能力。
优化相似度计算:
- 提高余弦相似度的准确性: 余弦相似度是衡量两个向量方向之间夹角的余弦值,常用于计算文本、图像等嵌入的语义相似性。当向量未归一化时,向量的长度(magnitude)会影响点积的值,从而影响余弦相似度的结果。归一化后,向量的长度变为 1,此时余弦相似度就直接等于向量的点积,能够更准确地反映向量方向上的相似程度。
- 改善基于距离的度量: 对于依赖欧氏距离等距离度量的算法(如 K-近邻、K-均值聚类),归一化可以确保距离的计算不会被尺度较大的特征所主导,从而得到更符合语义或特征实际分布的结果。
稳定模型训练,加速收敛:
- 避免梯度爆炸或消失: 在神经网络训练中,如果输入的特征尺度过大或过小,可能导致梯度在反向传播过程中变得非常大(梯度爆炸)或非常小(梯度消失),从而影响模型的收敛速度和训练稳定性。归一化可以将输入特征限制在合理的范围内,有助于缓解这些问题。
- 加快收敛速度: 当特征具有相似的尺度时,梯度下降等优化算法可以更有效地找到最优解,因为模型不需要在不同尺度的特征空间中来回震荡。
提高模型性能和泛化能力:
- 减少模型对异常值的敏感性: 某些归一化方法(如 Z-score 归一化)可以降低异常值对模型的影响,使模型更加稳定。
- 提升模型在不同数据集上的泛化能力: 通过统一特征的尺度,归一化可以帮助模型学习到更通用的模式,而不是过度依赖于特定数据集的尺度分布。
方便不同嵌入模型的比较和集成:
- 统一不同模型的输出尺度: 不同的嵌入模型可能产生具有不同尺度范围的向量。归一化可以将它们的输出统一到一个共同的尺度,使得可以直接比较或组合来自不同模型的嵌入,从而进行更复杂的分析或构建更强大的系统。
总结
归一化是处理嵌入向量的一个关键步骤,它可以确保相似度计算的准确性,优化模型训练过程,提高模型性能和泛化能力,并方便不同嵌入之间的比较和集成。在大多数使用嵌入向量的机器学习和深度学习应用中,都强烈建议进行归一化处理。最常用的归一化方法是 L2 归一化,它将向量的长度缩放为单位长度。
2、向量相似度
相似度量用于衡量向量之间的相似性。选择合适的距离度量有助于显著提高分类和聚类性能。向量的相似度量有:余弦相似度(Cosine Similarity)、内积(Inner Product, IP)、欧氏距离(Euclidean Distance)、曼哈顿距离(Mahalanobis Distance)、余弦距离(Cosine Distance)、汉明距离(Hamming Distance)、Jaccard 相似度(Jaccard Similarity)、BM25 相似度(BM25 Similarity)等等。
余弦相似度(Cosine Similarity):
Cosine(A, B) = (A · B) / (||A|| * ||B||)。它衡量的是两个向量方向上的一致性,忽略了向量的长度(模长)。它的取值范围是 [-1, 1],越接近 1 表示方向越一致。 例如,两个正比向量的余弦相似度为1,两个正交向量的余弦相似度为0,两个相反向量的余弦相似度为-1,余弦越大,两个向量之间的夹角越小,说明这两个向量之间的相似度越高。 用 1 减去它们的余弦相似度,就可以得到两个向量之间的余弦距离。
RAG
RAG (Retrieval-Augmented Generation),中文可以理解为检索增强生成,是一种通过从外部知识库检索信息来增强大型语言模型(LLM)能力的AI框架。
简单来说,传统的 LLM 是基于其训练数据来生成文本的,而 RAG 则在此基础上增加了一个步骤:当用户提出问题或指令时,RAG会先从外部的信息源(比如网页、数据库、文档等)中搜索相关的知识,然后将这些检索到的信息与用户的问题一起提供给 LLM,让 LLM 在生成答案时能够参考这些外部信息
RAG的主要步骤可以概括为:
- 检索 (Retrieval): 接收用户的查询,并从外部知识库中找到与之相关的信息。这通常涉及到信息检索技术,例如关键词搜索、向量搜索等。
- 增强 (Augmentation): 将检索到的相关信息与用户的原始查询结合起来,形成一个更丰富的输入(通常称为提示,Prompt),提供给 LLM。
- 生成 (Generation): LLM 接收到增强后的输入,并基于这些信息生成最终的回答或文本。
使用RAG的好处包括:
- 获取最新的信息: LLM的训练数据通常是静态的,而RAG可以实时地从外部获取最新的信息,从而生成更准确、及时的回答。
- 减少“幻觉”: 通过引用外部的可靠信息来源,RAG可以降低LLM生成不真实或不相关信息的风险。
- 提高透明度: 在某些情况下,RAG可以提供生成答案所依据的外部信息来源,帮助用户验证答案的可靠性。
- 降低计算成本: 相比于重新训练整个LLM来使其掌握新知识,RAG的成本通常更低。
- 适应特定领域: RAG可以连接到特定的知识库,例如企业内部文档或专业领域的数据库,从而使LLM在这些特定领域内提供更专业的回答。
RAG的一些应用场景包括:
- 智能客服: 能够根据最新的产品信息、FAQ等知识库回答用户的问题。
- 问答系统: 能够从大量的文档或数据中检索并生成针对特定问题的答案。
- 内容创作: 能够基于最新的研究报告或新闻资讯生成文章或报告。
总而言之,RAG通过将LLM的生成能力与信息检索系统的知识获取能力相结合,使得AI能够生成更准确、更可靠、更具上下文相关性的文本。
模型微调
模型微调 (Fine-tuning) 则是指在预训练好的大型语言模型的基础上,使用一个较小但更 específico 的数据集进行额外的训练,以使模型更好地适应特定的任务或领域。这个过程会调整模型内部的权重和参数,使其学习到目标任务的特定模式和知识。
模型微调相较于RAG,在难度和不利方面主要体现在以下几点:
难度:
- 数据准备和标注: 模型微调通常需要一个高质量、与目标任务高度相关的标注数据集。收集、清洗和标注这些数据可能非常耗时、昂贵且困难,尤其是在某些专业领域。RAG主要依赖于构建和维护一个可搜索的知识库,对数据的标注要求通常较低。
- 专业知识: 微调需要对自然语言处理(NLP)、深度学习以及模型架构有一定的理解,才能选择合适的微调策略、调整超参数并评估模型性能。RAG的实现则更侧重于信息检索系统的构建和与LLM的集成。
- 实验和调优: 微调过程可能需要多次实验才能找到最佳的模型配置和超参数,以避免过拟合或欠拟合,并获得理想的性能。RAG的调优主要集中在检索策略和生成提示的优化上。
- 计算资源: 对大型LLM进行微调需要大量的计算资源(GPU/TPU)和时间,尤其是在处理大型数据集时。RAG在推理阶段的计算成本主要在于检索和生成答案,通常低于重新训练整个模型。
不利的地方:
GGUF 格式
LLM GGUF 格式是一种用于存储大型语言模型(LLM)的文件格式,特别是那些与 Llama.cpp 库一起使用的模型。GGUF 是 “GG Ultra Fast” 的缩写,它旨在提供一种高效且可移植的方式来存储和加载 LLM。
GGUF 格式的关键特性包括:
-
高效性: GGUF 格式的设计考虑了性能,允许 Llama.cpp 快速加载和处理模型数据。
-
可移植性: GGUF 文件可以在不同的硬件和操作系统之间共享,从而提高了 LLM 的可用性。
-
灵活性: GGUF 格式支持各种模型架构和数据类型,使其能够适应不断发展的 LLM 领域。
-
向后兼容性: GGUF 格式设计为向后兼容,这意味着新版本的 Llama.cpp 仍然可以读取旧版本的 GGUF 文件。
总而言之,GGUF 格式是一种专门为 LLM 设计的存储格式,它强调效率、可移植性和灵活性。它在 Llama.cpp 生态系统中被广泛使用,并帮助实现了各种设备上 LLM 的高效部署。
使用 GGUF 格式
Model 转换工具
Hugging Face 平台为使用 Llama.cpp 进行模型转换、量化和托管提供了各种在线工具:
GGUF-my-repo space:用于转换为 GGUF 格式,并将模型权重量化为更小的尺寸。
Llama.cpp 和 Ollama 都是在本地运行大型语言模型(LLMs)的工具,但它们的设计目标和使用方式有所不同。以下是它们之间的主要区别:
- 设计目标:
- Llama.cpp:
- Llama.cpp 是一个用 C++ 编写的库,专注于在消费级硬件(尤其是 CPU)上实现高性能的 LLM 推理。
- 它的目标是提供一个轻量级、高效的解决方案,允许开发者在本地运行 LLMs,而无需依赖强大的 GPU。
- Llama.cpp 的核心是提供一个高效的运行LLM的工具,可以理解为是一个底层的工具。
- Ollama:
- Ollama 则是一个更高级别的工具,旨在简化在本地运行 LLMs 的过程。
- 它使用 Llama.cpp 作为其后端之一,提供了一个易于使用的命令行界面和 API,允许用户快速下载、运行和管理 LLMs,而无需深入了解底层细节。
- Ollama 的核心是提供一个简易的LLM运行,下载,管理的工具,可以理解为是一个上层的工具。
- 使用方式:
- Llama.cpp:
- Llama.cpp 主要是一个库,开发者可以将其集成到自己的应用程序中。
- 它也提供了一些命令行工具,但主要用于测试和演示。
- Llama.cpp 需要用户对命令行和模型文件有一定的了解。
- Ollama:
- Ollama 提供了一个更友好的用户体验,用户可以通过简单的命令下载和运行 LLMs。
- 它还提供了一个 API,允许开发者将 LLMs 集成到自己的应用程序中。
- Ollama 简化了 LLMs 的安装和运行过程,降低了使用门槛。
- 功能:
- Llama.cpp:
- Llama.cpp 专注于提供高性能的 LLM 推理,支持多种量化和优化技术。
- 它对底层硬件进行了优化,以实现最佳性能。
- Ollama:
- Ollama 除了提供 LLM 推理功能外,还提供了模型管理、API 服务等功能。
- 它旨在提供一个完整的 LLM 运行环境。
- 总结:
- 如果您是开发者,需要将 LLMs 集成到自己的应用程序中,并且对性能有较高要求,那么 Llama.cpp 可能更适合您。
- 如果您是普通用户,希望快速、方便地在本地运行 LLMs,那么 Ollama 可能更适合您。
- 简单来说,Llama.cpp 是一个更底层的工具,而 Ollama 则是一个更上层的工具。
GraphRAG
-
核心理念: GraphRAG 是一种检索增强生成(RAG)技术,它利用知识图谱来增强大型语言模型(LLM)的性能。
-
工作原理:
- 它从知识图谱中检索相关信息,并将其作为上下文提供给 LLM。这有助于 LLM 更准确、更全面地回答问题,尤其是在需要复杂推理或涉及实体关系时。
-
优势:
- 增强了 LLM 的事实准确性和知识覆盖面。
- 提高了处理复杂查询和推理的能力。
- 能够更好地理解实体之间的关系。
-
应用场景:
- 金融分析、医疗保健、法律等需要精确知识和推理的领域。
- 在处理具有复杂关系的数据时,例如社交网络分析。
-
特点:
- 通过知识图谱来提高数据的关系性和准确性。
- 需要构建和维护知识图谱。
AnythingLLM
-
核心理念: Anything LLM 是一种开源平台,旨在简化 LLM 与各种数据源的集成。
-
工作原理:
- 它允许用户连接各种数据源(如文档、网站、数据库等)。
- 然后,它使用 RAG 技术从这些数据源中检索相关信息,并将其提供给 LLM。
-
优势:
- 易于使用,无需编码即可连接数据源。
- 支持多种数据源,具有很强的灵活性。
- 开源,允许用户自定义和扩展。
-
应用场景:
- 构建问答系统、聊天机器人、文档摘要等。
- 在需要从多个数据源检索信息的场景中。
-
特点:
- 可以连接多种数据源。
- 拥有友好的UI界面,容易上手。
- 开源项目,具有活跃的社区。
-
主要区别
- GraphRAG 的重点是利用知识图谱,而 Anything LLM 的重点是简化数据源集成。
- GraphRAG更侧重于提高LLM的推理能力,而AnythingLLM更侧重于提高LLM的信息检索能力。
- GraphRAG通常需要构建知识图谱,而AnythingLLM则更加的通用,可以连接多种数据源。
-
总结
- 如果需要利用知识图谱来提高 LLM 的推理能力,GraphRAG 可能是一个不错的选择。
- 如果需要一个易于使用的平台来连接各种数据源,Anything LLM 可能更适合。